Abstract
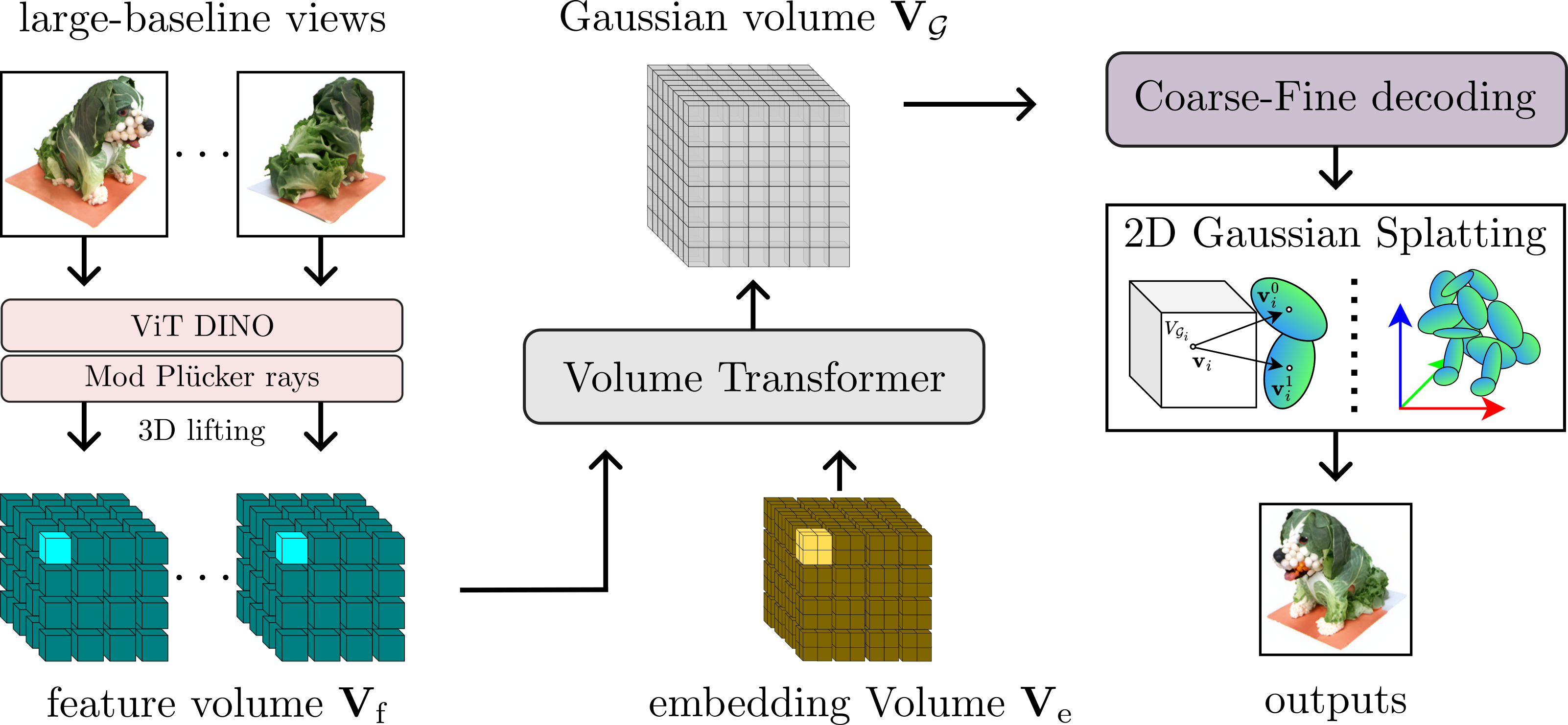
Radiance field methods have achieved photorealistic novel view synthesis and geometry reconstruction. But they are mostly applied in per-scene optimization or small-baseline settings. While several recent works investigate feed-forward reconstruction with large baselines by utilizing transformers, they all operate with a standard global attention mechanism and hence ignore the local nature of 3D reconstruction. We propose a method that unifies local and global reasoning in transformer layers, resulting in improved quality and faster convergence.